sudo apt update
# zsh installieren
sudo apt install zsh
chsh -s $(which zsh)
# eine neue shell aufmachen oder neu einloggen
# dann #2 auswählen
# "Oh-My-ZSH" installieren
sudo apt install git-core curl
sh -c "$(curl -fsSL https://raw.github.com/robbyrussell/oh-my-zsh/master/tools/install.sh)"
# Theme ändern
nano ~/.zshrc
# im editor die Zeile ändern:
ZSH_THEME="gnzh"
# mit ctr+x und y beenden und speichern
source ~/.zshrc
# Auto-Suggestions installieren
git clone https://github.com/zsh-users/zsh-autosuggestions ${ZSH_CUSTOM:-~/.oh-my-zsh/custom}/plugins/zsh-autosuggestions
nano ~/.zshrc
# im editor die Zeile ändern:
plugins=(
git
zsh-autosuggestions)
# mit ctr+x und y beenden und speichern
source ~/.zshrc
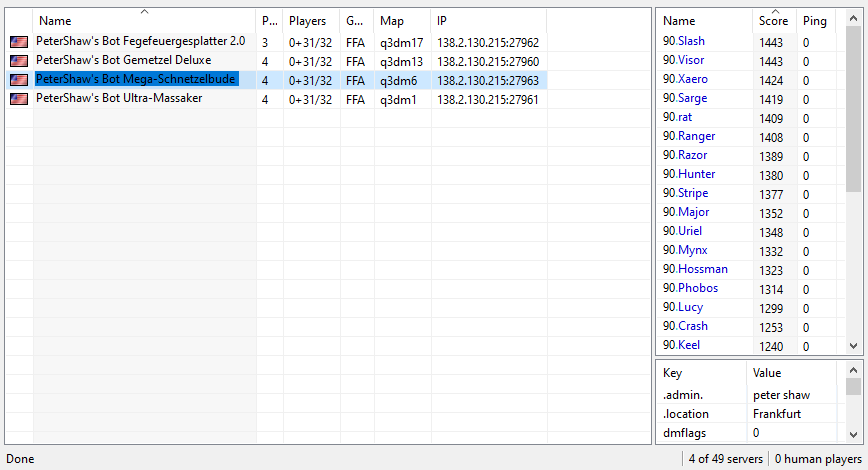
Bei Oracle gibt es umsonst**(**Man muss nur seine Kreditkartendaten hinterlegen) sogenannte „Cloud-Compute-Instanzen“. Neben ziemlich lahmen 1-Kern-AMD64 VMs gibt es auch relativ schnelle 4-Kern ARM (Ampere) Instanzen mit 24 GB RAM. Was kann man damit machen? Zum Beispiel einen Quake 3 Dedicated Server betreiben. Oder gleich mehrere. Auf meiner VM laufen aktuell 4 FFA-Server mit jeweils 31 Bots, die sich bis in alle Ewigkeit immer wieder in die ewigen Jagdgründe befördern:
Zunächst besorgt man sich Oracle Cloud Free Tier, startet eine Ampere (ARM)-Instanz und installiert Ubuntu Server drauf. Anleitungen gibt’s im Netz zuhauf.
Als nächstes muss man die Quake3-Executable für die ARM/AARCH64-Architektur kompilieren. Das folgende Script benutzt dafür den source code von quake3e:
sudo apt update && sudo apt upgrade
# Install dependencies
sudo apt install libsdl2-dev make gcc libcurl4-openssl-dev mesa-common-dev
sudo apt install libxxf86dga-dev libxrandr-dev libxxf86vm-dev libasound-dev
cd
mkdir q3
cd q3
mkdir baseq3
cd baseq3
# Download pk0 - pk8.pk3 from public website
wget http://quake3.bomping.se/baseq3/pak0.pk3 --continue
wget http://quake3.bomping.se/baseq3/pak1.pk3 --continue
wget http://quake3.bomping.se/baseq3/pak2.pk3 --continue
wget http://quake3.bomping.se/baseq3/pak3.pk3 --continue
wget http://quake3.bomping.se/baseq3/pak4.pk3 --continue
wget http://quake3.bomping.se/baseq3/pak5.pk3 --continue
wget http://quake3.bomping.se/baseq3/pak6.pk3 --continue
wget http://quake3.bomping.se/baseq3/pak7.pk3 --continue
wget http://quake3.bomping.se/baseq3/pak8.pk3 --continue
cd
# get Quake3e source code and compile
git clone https://github.com/ec-/Quake3e
cd Quake3e
make USE_RENDERER_DLOPEN=0 RENDERER_DEFAULT=vulkan
make install DESTDIR=../q3 USE_RENDERER_DLOPEN=0 RENDERER_DEFAULT=vulkan
Nun muss man noch die Ports freischalten – Sowohl im Webinterface von Oracle Cloud als auch in der Firewall der Ubuntu-VM. Standardmäßig benutzt Quake 3 die Ports 27960 aufwärts, ich habe also 27960 – 27965 freigegeben – Diese Anleitung kann als Grundlage benutzt werden. Siehe Punkt 3 (create an ingress rule) sowie 4.8 (update firewall settings). Man muss die ports sowohl als TCP als auch als UPD freigeben. Zuletzt startet man den Server – am besten mit einem Bash-Script, wie hier beschrieben.
Raspberry Pi 4 – Quake 3 mit Vulkan Renderer
Mit demselben Script erhält man auf einer Raspberry Pi4 übrigens einen Quake 3 Client mit Vulkan-Renderer! Dazu müssen noch die Vulkan-Treiber installiert werden:
Ich habe einige GigaByte an „Raw“-Filmdateien aus meiner Nikon D3200 (720p, 50 fps, AVC) – Will man diese Daten als Backup sichern, stellt sich zumindest bei einem zusätzlichen Cloud-Backup die Frage, ob es nicht Sinn macht, die Raw-Daten in ein verlustbehaftetes Format zu (re-)encoden. Folgende Codecs kommen in Frage:
h264 (AVC)
Dies ist der derzeit geläufigste Codec. Vorteile sind seine Schnelligkeit und sehr hohe Kompatibilität. Der Codec ist schon ziemlich alt (fast 20 Jahre) und dadurch im Vergleich nicht sehr effizient.
h265 (HEVC)
wie schon der Name verrät, ist das der Nachfolger von h264. Im Jahr 2013 erschienen und durch seine höhere Komplexität viel effizienter. Allerdings dauert das encoden auch länger.
av1 (av1-AOM und av1-SVT)
Der relativ neue Codec aus dem Jahr 2019 schlägt in Effizienz wiederum h265, die Encode-Zeiten sind je nach Setting und verwendetem Encoder allerdings noch einmal deutlich länger. Youtube und Netflix benutzen diesen Codec schon bei ausgewähltem Content und auf ausgewählten Devices.
Testvideo
Als Testmaterial habe ich ein Video, das ich 2019 in den USA gemacht habe, ausgewählt: Das sehr wackelige 720p 50-fps Video zeigt einen Buckelwal, der aus dem Wasser springt – und ist wohl recht anspruchsvoll, was die Encodierungsqualität angeht. Aufgrund der niedrigen Auflösung gehe ich allerdings davon aus, dass viele Vorteile der neuesten Codes, die ja ihre Stärken bei UHD-Content ausspielen, nicht zur Geltung kommen werden.
Ziel war es, die Datenmenge auf ca. 1/3 zu reduzieren. Für die obige Datei bedeutet das also von 30 MB auf 10 MB. Dass das mit h264 ohne allzu große Abstriche möglich ist, wusste ich bereits aus einem früheren Versuche: Vor einigen Jahren hatte ich ohne große Einarbeitung in die Materie mit einem FFMpeg-Script alle meine Daten in h264 umgewandelt. Mit dem Ergebnis war ich sowohl bezüglich der Dateigröße (ca. 1/3) als auch der Qualität zufrieden. Die Encoder-Settings konnte ich durch herumprobieren rekonstruieren: x264, Preset slower, CRF 21.
Wie schlägt sich der in die Jahre gekommene Codec aber gegen die beiden neueren Codecs h265 und av1?
Zum Vergleich der Qualität wurde das Tool FFMetrics in der Version 1.3.1b2 benutzt, insbesondere die VMAF-Scores waren für mich von Interesse. VMAF ist eine von Netflix entwickelte und oft für Streaming-Qualitätsvergleiche herangezogene objektive Metrik.
Wie erwartet gilt: neuer Codec=bessere Qualität bei gleicher Dateigröße=längere Encode-Dauer. Überrascht hat mich allerdings, dass Preset-Werte von > 3 (AOM) bzw. > 4 (SVT) schlechtere VMAF-Werte als bei der h265-Referenz produzierten – Erst bei schmerzhaft niedrigen Preset-Werten, welche eine entsprechend lange Encode-Zeit bedeuten, wurde h265 in dieser Metrik geschlagen. Meine Vermutung ist, dass das an der niedrigen Auflösung (720p) liegt. Der neuere Codec spielt seine Stärken wohl erst bei sehr hohen Auflösungen aus. Allerdings sind die beiden anderen Metriken (PSNR und SSIM) durch die Bank bei den neuen Codecs höher. Diese Metriken sind allerdings in ihrer Aussagekraft umstritten.
Für meinen use-case bedeutet das nun, dass sich der av1-Codec angesichts der astronomisch langen Encode-Zeiten nicht lohnt, und ich stattdessen mit dem bewährteren h265-Codec (preset slow) ins Rennen gehen werde. Eine vollständige Tabelle mit PSNR, SSIM und VMAF-Werten gibt es hier.
batch reencode
Dieses Bash-Script durchsucht alle Unterordner des aktuellen Verzeichnisses nach .mov-Dateien und encoded diese dann mit ffmpeg, die Zieldatei landet im selben Ordner:
#für die beiden anderen Codecs würde die Befehlszeile so aussehen:
./ffmpeg -i .\wal.mov -map 0 -c:v libsvtav1 -preset 4 -crf 25 -svtav1-params tune=0 -pix_fmt yuv420p10le -vf scale=in_range=limited:out_range=limited -c:a libopus -b:a 192k -vbr on av1-svt-4-25.mp4
./ffmpeg -i .\wal.mov -map 0 -c:v libaom-av1 -cpu-used 3 -crf 22 -b:v 0 -pix_fmt yuv420p10le -vf scale=in_range=limited:out_range=limited -c:a libopus -b:a 192k -vbr on av1-aom-3-22.mp4
Nachtrag
Wie man gesehen hat, ist der VMAF-Score Abstand zwischen dem in die Jahre gekommenen h264-Codec und den beiden neueren Codecs bei gleicher Dateigröße doch recht hoch (93.4 zu ~ 95.0). Rein aus Interesse habe ich getestet, wie groß ein h264-Encode sein muss, um auch einen VMAF-Score von ~ 95.0 zu erreichen:
Wer oft den Raspberry OS Standard-Datei-Manager PCManFM benutzt, kennt dessen Unzulänglichkeiten (Abstürze, keine Tabs, bei Vor-/Zurück-Commands wird das zuletzt markierte Element verworfen, keine Geschwindigkeitsanzeige beim Kopieren, etc pp). Stattdessen kann man z.B. „Thunar“ nachinstallieren
sudo apt get update
sudo apt install thunar
Ziemlich praktisch ist die Möglichkeit, „Custom Actions“ zu definieren. Beispielhaft im Folgenden mal zwei praktische Custom Actions:
Thunar kann man nun über das Start Menü > System Tools starten. Unter Edit > Configure Custom Actions die Aktion „Open Terminal Here“ mit einem Tastenkürzel (z.B. F4) versehen.
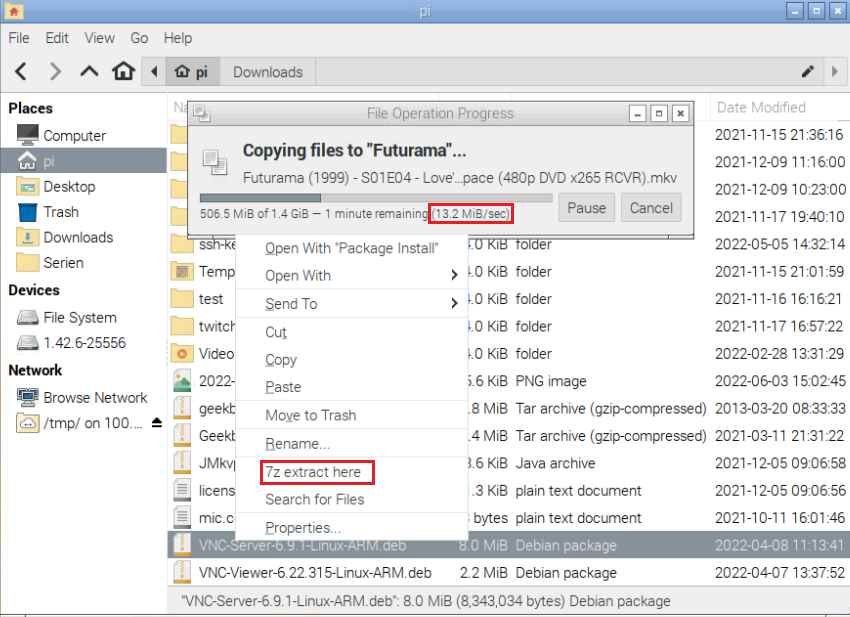
mit 7zip ein Archiv in den aktuellen Ordner extrahieren
sudo apt-get install p7zip-full
in Thunar unter Edit > Configure Custom Actions eine neue Aktion hinzufügen: name: 7z extract here command: x-terminal-emulator -e "7z x %F -y"
unter dem Tab „Appearance Conditions“ dann noch „Other Files“ auswählen.
Das praktische Tool „Bulk Rename“ (im Start Menü unter System Tools) wird übrigens gleich mitinstalliert.
Völlig überraschend und ohne Vorankündigung hat die Raspberry Pi Foundation am 29.10.21 den Zero 2 W herausgebracht. Ich habe direkt meine 3 alten Pi Zeros verkauft und mir ein Upgrade gegönnt. Ich will hier mal alles Interessante auflisten, was mir bei der Benutzung des Zero 2 in den letzten Tagen aufgefallen ist:
Performance
Der neue Pi Zero 2 ist durch seine 4 CPU-Cores je nach use-case ~ 2-4 mal schneller als sein Vorgänger. Als Desktop-Ersatz, was für mich auch immer Web-Browsen beinhaltet, ist er aber aufgrund des kleinen Arbeitsspeichers nach wie vor nicht geeignet. Beispiel: Chromium zu starten dauert 15 Sekunden, bis die YouTube-Startseite mit allen Thumbnails geladen ist, wartet man 30 Sekunden. Aber für 15€ muss man seine Erwartungen auch etwas zügeln.
Webbrowser-Ersatz
Um trotzdem etwas im Internet Surfen zu können, habe ich den Lightweight-Browser NetSurf installiert. Da das noch nicht in den Repositories ist, muss man es selbst kompilieren (dauert ca. 10 Minuten):
wget http://download.netsurf-browser.org/netsurf/releases/source-full/netsurf-all-3.10.tar.gz
sudo apt update
sudo apt install flex bison gperf libcurl4-gnutls-dev libgtk2.0-dev libhtml-parser-perl libjpeg-dev
tar xzf netsurf-all-3.10.tar.gz
cd netsurf-all-3.10
make && sudo make install
NetSurf startet man dann mit netsurf-gtk2. Unter Edit->Preferences sollte man noch JavaSctipt aktivieren. Eine weitere Browser-Alternative ist luakit. Das kann mit mit sudo apt install luakit installieren
Stromverbrauch
Die höhere Leistung führt leider auch zu einem höheren Stromverbrauch, was jedoch nur bei Akku-Betrieb relevant ist.
Zero 1 W
0,9 W
Zero 2 W (1 Core)
1,0 W
Zero 2 W (4 Cores)
2,2 W
CPU-Stress-Test
Der Idle-Stromverbrauch des Zero 2 ist nur unwesentlich höher als der des Zero 1 (0,5 W anstatt 0,4 W). Will man z.B. bei Timelapse-Projekten, bei denen es nicht auf die Leistung ankommt, noch etwas mehr Akkulaufzeit rauskitzeln, kann man 3 der 4 CPU-Kerne deaktivieren: Dazu editiert man die /boot/cmdline.txt und fügt maxcpus=1 hinter console=tty1 ein. Nach einem Neustart steht dann nur noch einer der 4 CPU-Cores zur Verfügung. Das führt dazu, dass im Falle eines CPU-Spikes weniger Strom verbraucht wird. Je nachdem, wie lange die Timelapse-Intervalle sind, könnte das relevant sein.
Generell kann der Zero 2 W, wie auch der Zero 1 W, an einem USB (2.0 oder 3.0)-Port z.b. eines Laptops betrieben werde, da er nicht mehr als 500 mA bei 5V = 2,5 W verbraucht.
Übertakten
Der Zero 2 ist ohne weiteres von 1,0 GHz auf 1,3 GHz übertaktbar. Dazu in der /boot/config.txt folgendes einfügen und neustarten
over_voltage=6
arm_freq=1300
Die CPU throttled dann unter Last entsprechend früher, bzw. wird schneller heiss. Mein Zero 2 läuft selbst ohne over_voltage auf 1,2 GHz in einem Standard-Gehäuse stabil. Idle-Temps ~ 42 °C.
Durch das Upgrade der CPU-Architektur ist es nun möglich, 64-Bit Betriebssysteme auf dem Pi Zero 2 zu installieren. Zum Zeitpunkt dieses Posts gibt es aber noch kein funktionierendes Raspberry Pi OS 64 bit (beta) Image. Durch einen Workaround kann man das aber auch jetzt schon auf dem Pi Zero 2 installieren. Dazu benötigt man einen Raspberry Pi 3. Auf diesem muss man das aktuelle Beta Image von Pi OS 64 installieren und vollständig updaten:
sudo apt update
sudo apt dist-upgrade
sudo apt autoremove
sudo rpi-update # (nur bei Raspberry Pi OS)
Dadurch werden die benötigten Device-Tree-Files für den Zero 2 geladen. Danach kann die SD-Karte in den Zero 2 eingesetzt werden.
Alternativ kann man, analog zur gerade beschriebenen Methode, Ubuntu Server 21.10 64 bit mit Hilfe eines Raspberry Pi 3, 4 oder 400 installieren.
Nach etlichen gescheiterten Versuchen, FreeFileSync auf meinem Pi4 zu kompilieren, bin ich auf diesen Beitrag im FreeFileSync-Forum von User „Olvin“ gestoßen. Er hat die Version 11.3 kompiliert und mit allen benötigten Libraries gezippt bereit gestellt. Allerdings auf einer russichen Upload-Seite. Deswegen hier als Mirror.
Die untenstehende Anleitung ist veraltet und gilt nur für Raspberry Pi OS Buster. Eine Anleitung für Rasperry Pi OS Bullseye gibt es hier.
Hier folgt die alte Anleitung für Rasperry Pi OS Buster:
Nachdem ich (erfolglos) etliche Anleitungen zum Installieren eines Nextcloud Clients für die Raspberry Pi ausprobiert habe, bin ich endlich auf folgende Lösung gestoßen:
Es werden insgesamt 4 Pakete benötigt. Mit wget Pakete herunterladen:
Um dir ein optimales Erlebnis zu bieten, verwenden wir Technologien wie Cookies, um Geräteinformationen zu speichern und/oder darauf zuzugreifen. Wenn du diesen Technologien zustimmst, können wir Daten wie das Surfverhalten oder eindeutige IDs auf dieser Website verarbeiten. Wenn du deine Zustimmung nicht erteilst oder zurückziehst, können bestimmte Merkmale und Funktionen beeinträchtigt werden.
Funktional
Immer aktiv
Die technische Speicherung oder der Zugang ist unbedingt erforderlich für den rechtmäßigen Zweck, die Nutzung eines bestimmten Dienstes zu ermöglichen, der vom Teilnehmer oder Nutzer ausdrücklich gewünscht wird, oder für den alleinigen Zweck, die Übertragung einer Nachricht über ein elektronisches Kommunikationsnetz durchzuführen.
Vorlieben
Die technische Speicherung oder der Zugriff ist für den rechtmäßigen Zweck der Speicherung von Präferenzen erforderlich, die nicht vom Abonnenten oder Benutzer angefordert wurden.
Statistiken
Die technische Speicherung oder der Zugriff, der ausschließlich zu statistischen Zwecken erfolgt.Die technische Speicherung oder der Zugriff, der ausschließlich zu anonymen statistischen Zwecken verwendet wird. Ohne eine Vorladung, die freiwillige Zustimmung deines Internetdienstanbieters oder zusätzliche Aufzeichnungen von Dritten können die zu diesem Zweck gespeicherten oder abgerufenen Informationen allein in der Regel nicht dazu verwendet werden, dich zu identifizieren.
Marketing
Die technische Speicherung oder der Zugriff ist erforderlich, um Nutzerprofile zu erstellen, um Werbung zu versenden oder um den Nutzer auf einer Website oder über mehrere Websites hinweg zu ähnlichen Marketingzwecken zu verfolgen.